Future Commit: vSLAM with neural network feature detection
Snapwhiz914 / October 2024 (471 Words, 3 Minutes)
Background
Shortly after I started the ScoutOdometry project, I learned that my school offers an Independent Study course. One of the papers I read when studying what vSLAM was linked to some interesting projects applying neural networks to vSLAM. An independent study project that brought together robotics and computer vision was too good of an opportunity to pass up, so I applied for the course with a very broad scope of “AI in vSLAM”. I was accepted and have narrowed the scope down to feature detection in domestic environments using neural networks.
Abstract
Feature Detection in Monocular Visual SLAM is the process of detecting and tracking points within a 2D image and using the movement of the points across a sequence of images to determine the relative movement of a camera. The application of Visual SLAM to robotics has existed for decades to enhance a robot’s ability to determine its location in an environment. Existing feature detection solutions are made to be generalizable to any environment, and may be less accurate for robotics applications which operate in a controlled environment. This project focuses on using Deep Learning methods to create a feature detector pipeline that is specialized to a specific environment, in this case a domestic one. Data is obtained synthetically through photorealistic 3D scenes or labeled 3D scans and used to train a neural network to label detected features. These labels are then assigned reliability ratings to designate the likelihood that the real world object of the feature changes position between video frames. For example, a feature labeled as a wall or floor is not likely to change its own position between camera frames, however a feature labeled as a human or a pet is far more likely to move. By adjusting the reliance placed on features based on their given labels, higher positional accuracy can be achieved.
Process
The process is more simple than I thought it be at first glance. I create multiple photorealistic, synthetic domestic scenes in Unity. Then I label the objects in the scene with tags like pet, furniture, floor, ceiling, etc., and record what the scene camera renders as well as the tags of every object in the frame.

On the left is a picture from the scene, and on the right is colors for every 10x10 patch of pixels that correspond to the tags for each object. For example, the dog is tagged as a pet and marked with orange, the floor is marked separately from the ceiling and walls with a dark blue color, etc.
Then I train a neural network on the images that I’ve collected to detect what patch of pixels corresponds to what kind of real-world object. Finally, I use the neural network in a pre-existing open source vSLAM stack – probably ORB-SLAM3 – to filter out features that correspond to dynamic objects such as pets and humans and only use static objects, like walls or floors.
Progress
So far I have one scene in Unity that is fully labeled. I have scripts in place to move the camera around and record as well as move the dog around, open doors and automatically tag objects. The next step is using more domestic scenes from the Unity Asset store, generating more training data and then training the network.
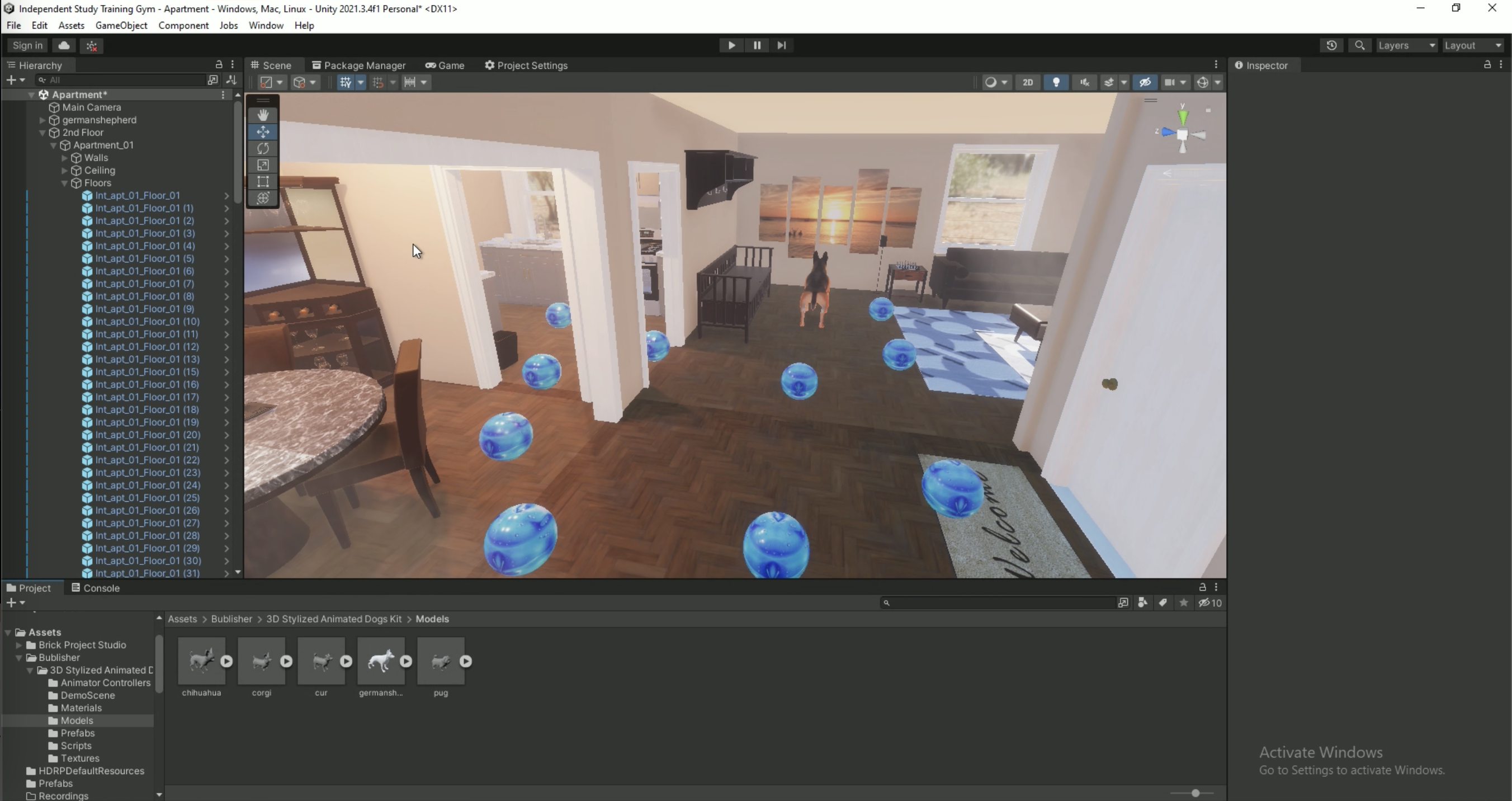
An example unity scene. The spheres that look like globes are the waypoints that the camera moves around between when recording (there is no reason in particular that they look like globes, it’s just more visually appealing than gray). Notice the sun shaft and light spots – lighting in Unity was a steeper learning curve but it was absolutely worth it to create these photorealistic effects.
Unlike the Lego Building Robot Arm project, I can promise that part 2 will be posted around mid-december.