Initial Commit: PN-API
Snapwhiz914 / August 2024 (523 Words, 3 Minutes)
Background
Along with my love for coding, I have a more recently discovered love of Cross Country running. About two years ago, I wanted to see if I could predict Cross Country races with data available on Milesplit and linear regression. I wrote a scraper and a prediction program in python (I will cover these in a later post), and one night I started the scraper on server2. When I woke next morning and checked the log, I was disappointed to see that I had hit the next-worst wall (the first being the paywall): the ratelimit.
I slowed down the requests, but I wasn’t satisfied with the just time.sleep(). I decided to switch gears entirely and turn my attention to the wonderful world of free proxies. Of course, please remember that PN-API is for educational purposes only. I not condone any wrongdoing committed using this software.
With that reminder, let’s begin.
Development process
In the beginning, I had only one goal: proxies that a python script could use to route requests through. To do that, I needed three things: proxy addresses, a checking process to ensure that they were valid, and a presentation medium. So the pipeline of a proxy address goes as follows: Source Scraping -> Checking -> Server API.
Sources
Initially, I had used HideMyName and PubProxy as my two primary sources. HideMy was not easy to scrape, and PubProxy did not yield very many working proxies. Those that did were barely on the edge of the 10 second default timeout for the request package. Fortunately, MhDDoS has an extensive list of sites that return proxy addresses in a nice txt format. In the current version (as of this post), I use exclusively this file for sources.
Checker
Checking for proxies turned out to be much more nuanced than I had originally thought. For example: do I consider a proxy working if it loads a page faster than 10 seconds just once? Should I test multiple requests in quick succession? How often should I check back on them? Are their IP addresses banned on popular sites due to previous wrongdoings? These are publicly accessible proxies, after all. The first few iterations only checked a proxy against httpbin, but this proved to be too generous. In the current version, a website must be able to load the homepages of Google and Reddit to be valid.
Server API
The original single-file version of PN was supposed to be just a library that could be imported by another python file, but I decided to take a step further and try out FastAPI for the first time while I was at it. That turned out to be a great decision, as it leaves open the possibility for PN to be constantly run on a server to keep a live list of working proxies.
Map UI
The current version actually has an HTML UI that uses the API to show where each proxy “is” (based on ipinfo.org) on a map of the world, as well as its speed and estimated anonymity (estimated via the results of httpbin). Looking back I really wished I had used an HTML framework to build it, but I’m happy with how it looks now.
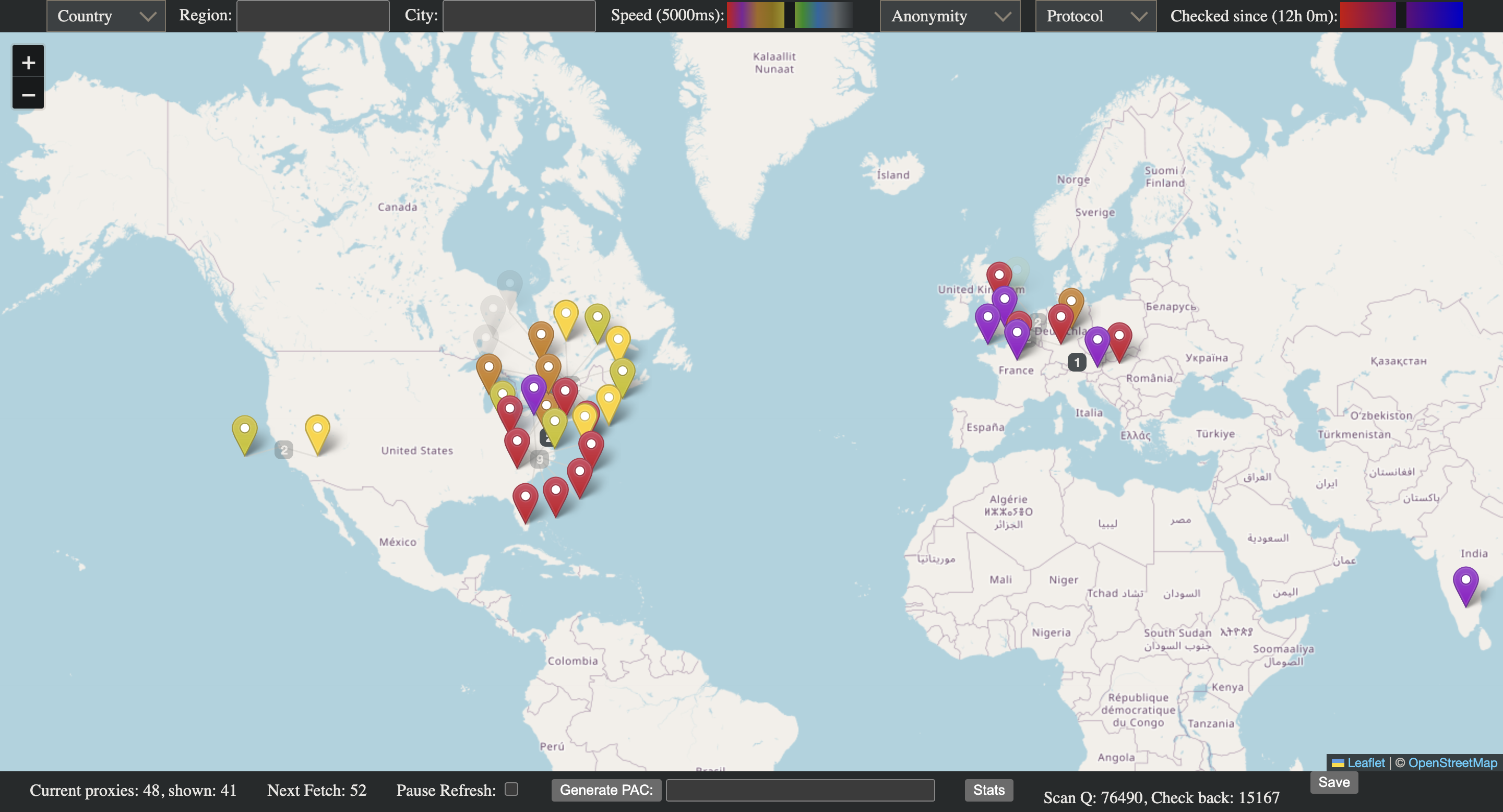
Screenshot of the Map UI. You will notice I am not a CSS expert.
Future plans
At this point, PN-API works well enough. It is not a single file, thankfully, but a multithreaded pipeline that flows as described above.
- One glaring problem is its inability to keep a live list after about a week, by which time the active list is full of proxies that haven’t been checked in over half a day. The timing and priority of checking back on working proxies could be thought out and re-implemented, but right now a simple restart will suffice.
- The codebase itself could use quite a bit of refactoring, especially in
main.pyandipinfo.py. - Keeping statistics of each proxy’s performance over time, as well as which source provides the most working proxies, in order to prioritize scans and check backs.